Main activities
Main activities
Our primary objective is to develop an automated approach for robust detection of vehicles in very high resolution satellite imagery. Evidently the ideal choice of methods for image analysis based vehicle detection depends on the conditions in the image, which again depends on location, type of road, traffic density, etc. We have decided to focus on typical Norwegian roads, which are characterized as narrow, curvy, and with low traffic density, compared to highways in other countries from which most published studies exist. Some of the main activities involved are:
The processing chain starts with a satellite image and some data files containing information about the geographical position of the road. This is a flow chart of the developed system:
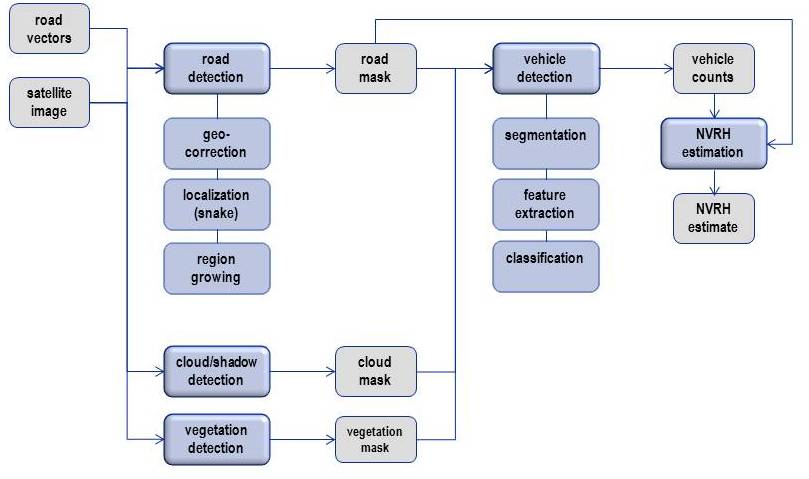
Vehicle detection: The vehicle detection module starts with segmentation, which means to partition the image into meaningful pieces. We work to develop a robust segmentation technique for the extraction of vehicle segments. The vehicles are characterized in the image as rectangular regions that are brighter or darker than the local background. However, due to the barely sufficient resolution of the satellite images for this application, the corners of the rectangular vehicles appear smoothed in the image, thus the interesting features can loosely be described as elliptical blobs whose gray level stand out from the surroundings. We use a scale space filtering technique and find elliptical image regions of uniform gray level by convolving the image with Laplacian of Gaussian filters over a range of scales, and comparing the convolution result to that expected for an ideal elliptical region of constant gray level.
The aim of the feature extraction step is to extract features from the segmented objects that may be used to distinguish vehicles from other segmented objects. Typically, such features are based on the shape and intensity of the segmented objects and contextual information related to the object. Using the extracted features we classify the object to a given vehicle type (car, truck, etc) or non-vehicle.
Road detection: The detection of vehicles from satellite images requires that the road to be analysed has been identified and masked out in the image. In the first phases of this project the roads have been manually identified. However, to make the vehicle detection into a fully automatic process, we have developed an automatic method for identifying the road in the image.
Vector data (GIS) of the roads to be analysed are delivered from the Norwegian Public Road Administration. The vector data are necessary both to identify the right roads, as there may be several roads covered by an image, and to find the position of the road in the image. If the images and vector data were completely co-registered, the road could be delimited simply by selecting an area corresponding to the width of the road around the vector data. Unfortunately, this is not the case, and for some of our images the deviation between the two can be up to a hundred meters.

Original road vector midline overlayed on multispectral image.
Although the vector data and image data are not accurately co-registered, the vector data still provides useful information about the approximate positions and directions of the road. We can therefore use this information to extract an area in the image around the road by re-sampling the image along lines perpendicular to the road vectors. The result of this transformation is a long and narrow image along the road. The re-sampled multispectral and panchromatic images are then analysed in order to segment the road. Using a snake model of the road, the corresponding road in the images is segmented using the Viterbi algorithm to find the optimal path.
Cloud detection: When using cloud contaminated images we need to construct a cloud and cloud shadow mask in order to (1) estimate observed road length such that the vehicle count estimate is not biased, (2) assist the vehicle detection algorithm by identifying road segments located in cloud shadow areas, and (3) assist the road segmentation algorithm by identifying road segments occluded by clouds.
To construct a cloud mask we apply a classification based approach, i.e. we aim for classifying the image into the following thematic classes: Clouds, cloud shadows, green vegetation, haze, and water. We have used a Gaussian distribution to model the respective classes, and the corresponding parameters were estimated from training data. The main challenge is that match between corresponding classes from the training data and the test data may be poor due to atmospheric, geographic, botanic, and phenologic variations in the image data. To solve this problem we model the test image using a Gaussian mixture distribution, and apply a low-rank model to estimate the parameters involved. The corresponding class-specific parameters are then directly given.